Шаг 1: Зарегистрируйтесь за минуту
Название компании, email, пароль — и у вас собственное рабочее пространство. Данные изолированы от других компаний. Готово к работе через 60 секунд.
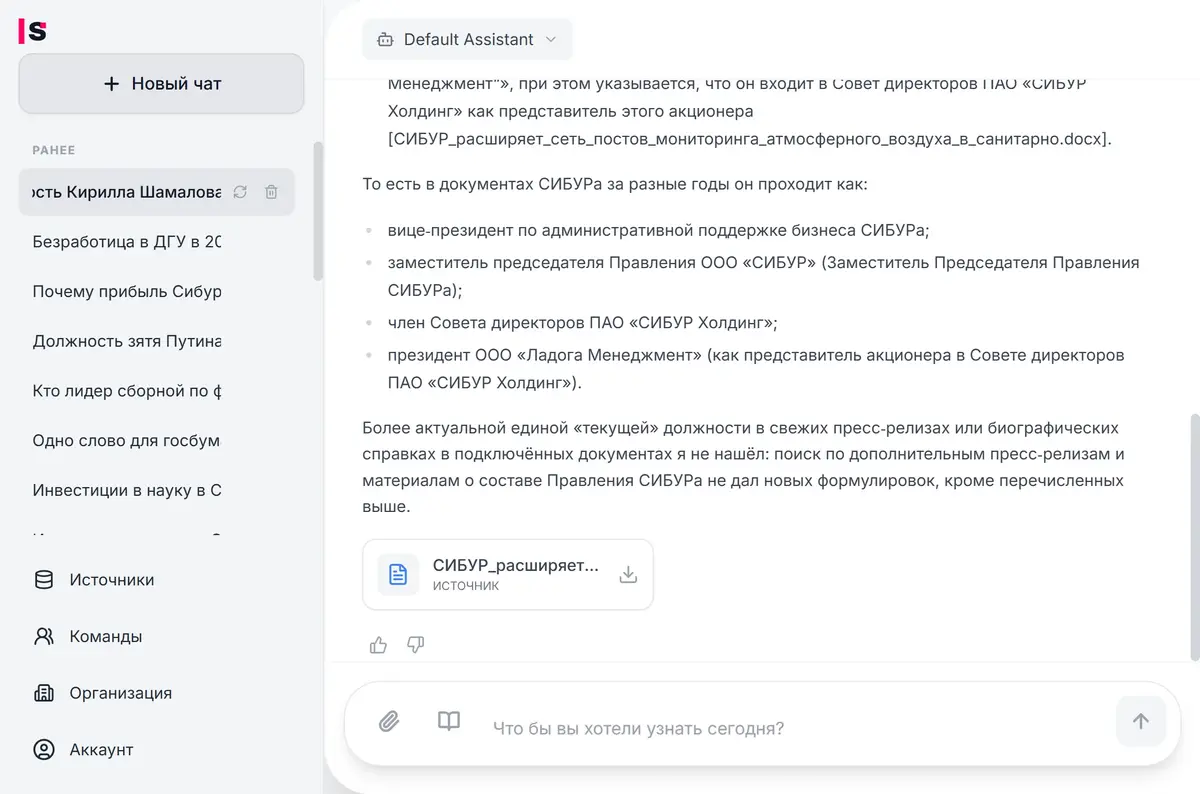
Находите информацию, получайте экспертный анализ и создавайте документы через диалог с ИИ
Название компании, email, пароль — и у вас собственное рабочее пространство. Данные изолированы от других компаний. Готово к работе через 60 секунд.
Отчёты, договоры, презентации, таблицы, сканы — платформа разберёт структуру и подготовит для работы с ИИ. До 400 МБ на файл. Таблицы и графики сохраняют структуру. Распознавание с точностью 96–100%.
ИИ-ассистент найдёт информацию, проанализирует и ответит с указанием источника. Поиск по смыслу, не по ключевым словам. Каждый ответ со ссылкой на страницу и фрагмент. Русский и английский язык.
Сравнить документы, найти риски, проверить по чек-листу — ИИ-ассистент разберёт сотни страниц за минуты. Сравнение версий и документов любого объёма. Таблицы, графики, сканы — видит и понимает. Каждый вывод — со ссылкой на источник.
Справка, сводная таблица, визуализация — ИИ-ассистент соберёт из ваших данных и оформит. Справки и сводные таблицы с экспортом в .xlsx. Изображения и визуализации на основе данных. Черновики по шаблону или свободному запросу.
Создавайте команды, назначайте роли и управляйте доступом к источникам. Три роли: владелец, админ, участник. Командные и личные пространства. Гибкие права на источники данных.
Подключайте отделы и интегрируйте с корпоративными системами. Яндекс Диск, Telegram, корпоративные хранилища. API для встраивания в ваши процессы. Шифрование данных, соответствие ФЗ-152.
Реальные задачи наших пользователей. Теперь решаются за минуты, а не часы.
«Открыл пять отчётов, чтобы найти одну цифру. Совещание через час»
«Три КП от поставщиков, у каждого свой формат. Сравниваю вручную»
«Нужен один пункт из 80-страничного договора. Открываю и листаю»
«"Где шаблон оффера?" — этот вопрос мне пишут каждую неделю»
«Простой вопрос по данным — жду ответ два дня»
Качество ответа определяется качеством подготовки данных. Многие решения игнорируют важность этого этапа и сталкиваются с проблемой Garbage in — garbage out. При загрузке документов SupaLab полностью разбирает их на слои, смыслы, факты и взаимосвязи — и организует правильное хранение для ИИ. Уже на базе этих подготовленных данных ИИ-ассистенты строят свою работу.
ИИ-ассистент берёт на себя рутину: находит информацию в документах, анализирует содержание, готовит справки и проверяет на соответствие требованиям. Он работает с вашей проектной, нормативной и внутренней документацией — доступен в любое время, не теряет контекст и не пропускает деталей.
Задайте вопрос на естественном языке — ИИ-ассистент найдёт ответ в ваших документах и укажет точный источник: документ, страницу, фрагмент.
ИИ-ассистент анализирует данные и смыслы — вы получаете структурированный анализ в нужном формате и объёме, с фактами и ссылками на страницы источников.
ИИ-ассистент подготовит текст, таблицу, визуализацию на основе ваших корпоративных данных.
| Поставщик | Срок | Сумма |
|---|---|---|
| ООО «Альфа» | 30 дней | 1.2 млн ₽ |
| ИП Иванов | 14 дней | 480 тыс ₽ |
| АО «Бета» | 45 дней | 3.7 млн ₽ |
Форматы
Многостраничные отчёты с плотными таблицами, сканированные документы, англоязычная отчётность.
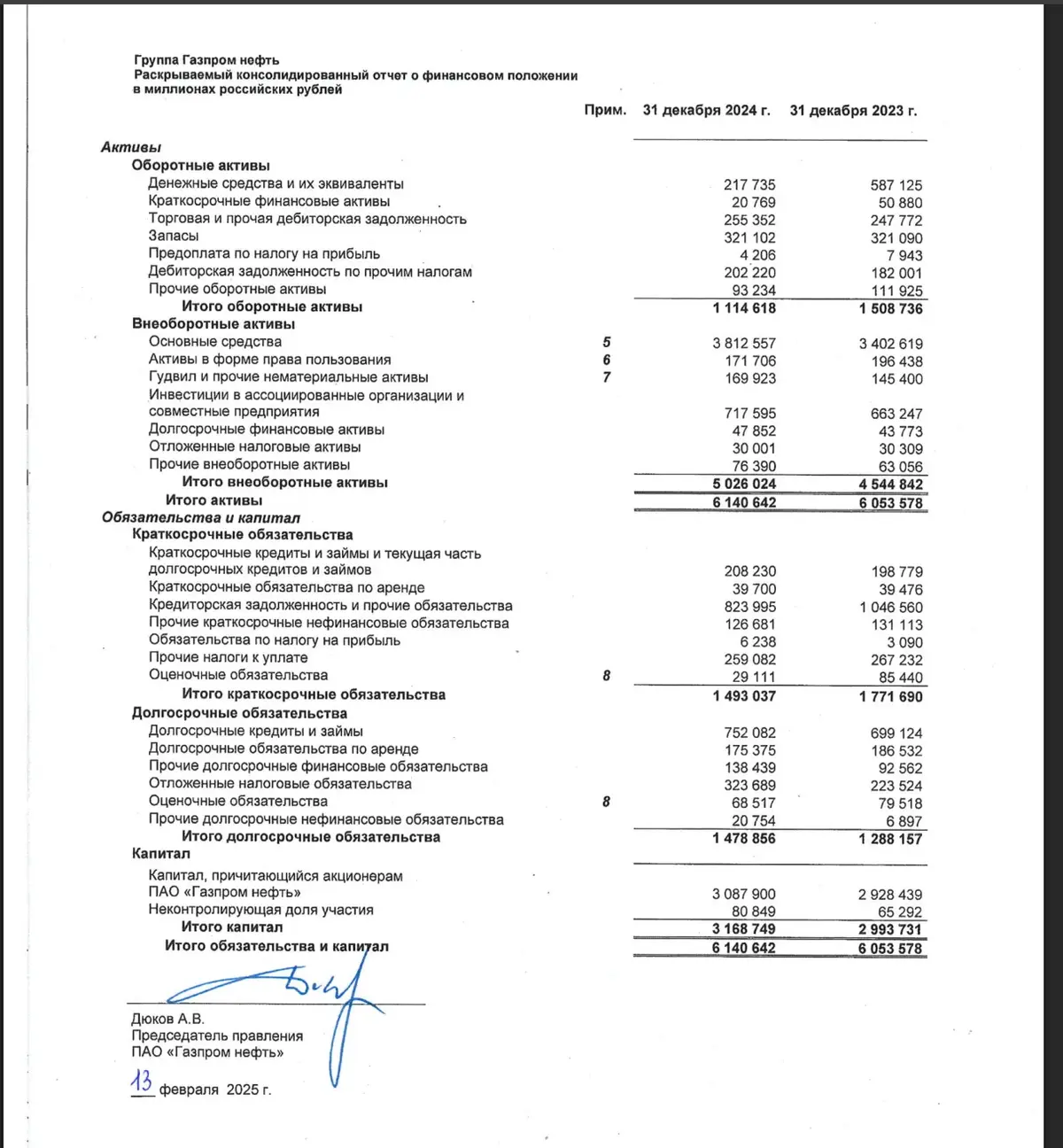
Консолидированные отчёты, балансы, движение капитала. Платформа извлекает структуру таблиц, связи между строками и сохраняет числовые данные без потерь.
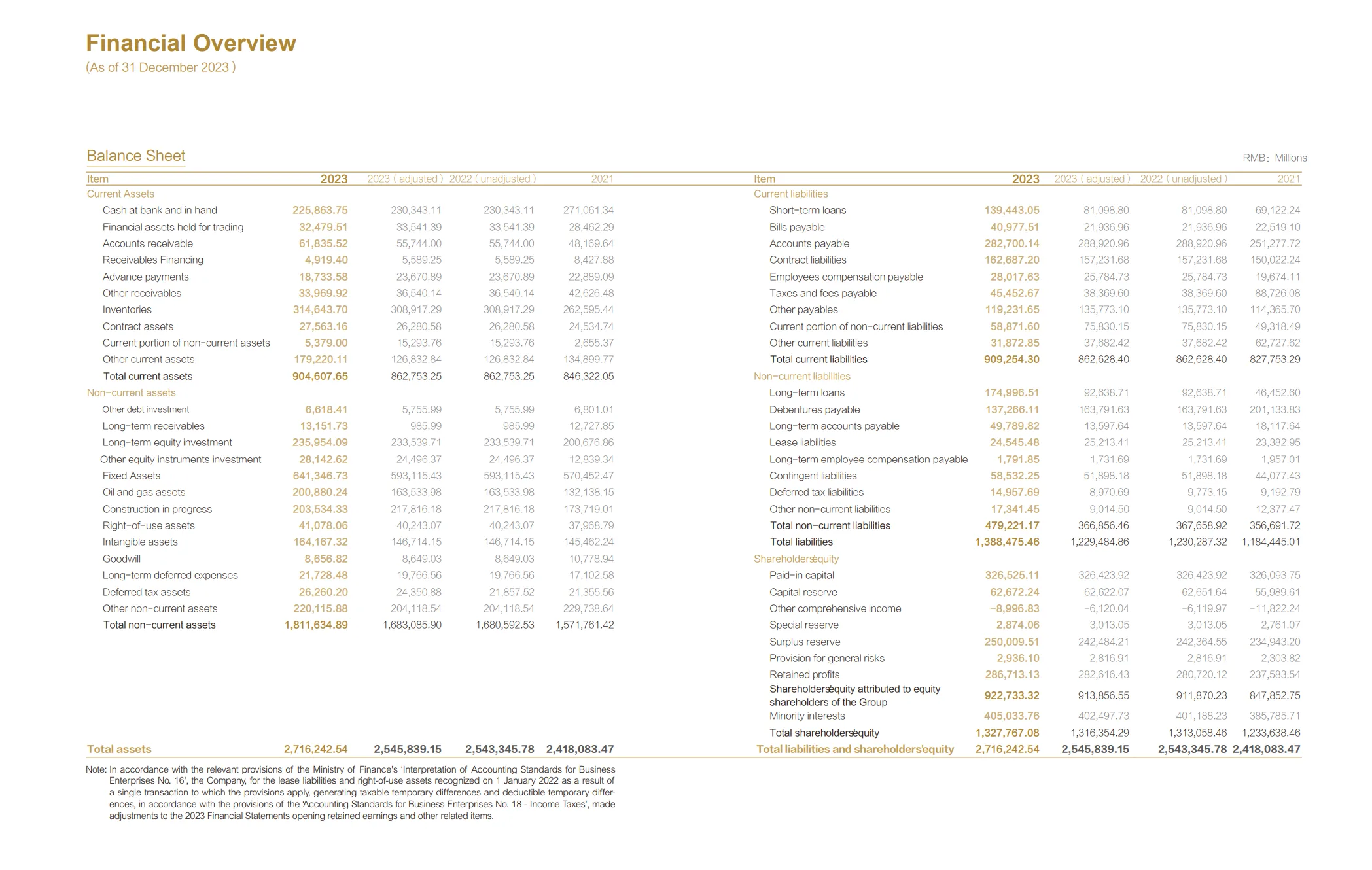
Слайды с визуализациями, диаграммами, инфографикой. ИИ «видит» графики и извлекает данные — не только текст, но и тренды, значения осей, легенды.
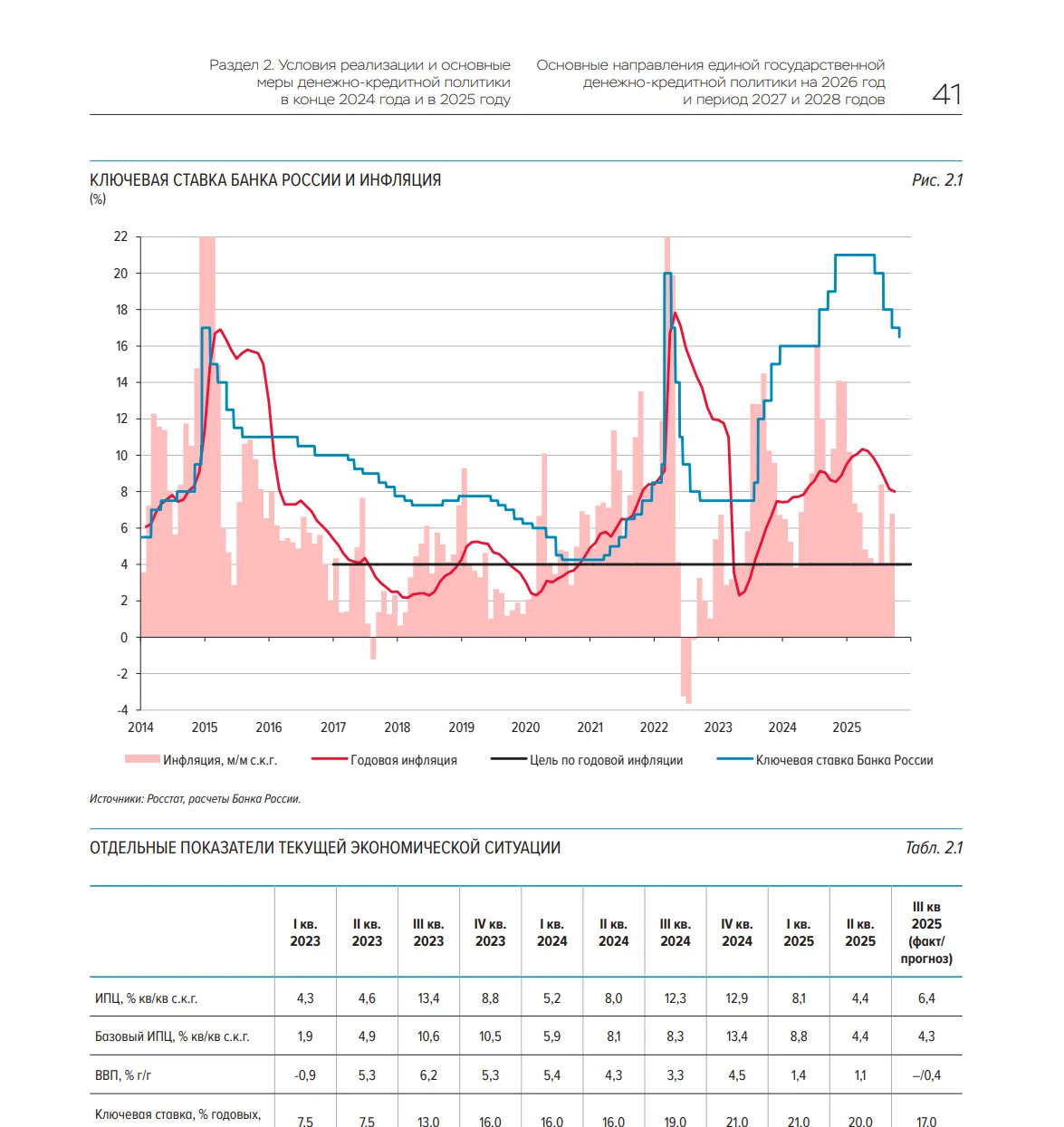
Для вашей компании
Юристы подключили свои документы, финансисты — свои. Теперь аналитик может задать вопрос по документам из обоих источников. Команды могут делиться источниками друг с другом — знания одного отдела становятся доступны всей компании.
Без затрат на внедрение и обучение. Загрузите документы — ассистент сам объяснит, что он умеет, и проведёт через первый запрос.
Три уровня: суперадмин компании, админ команды, пользователь. Каждый видит только те данные, которые ему разрешены. Начните с одной команды — масштабируйте, когда готовы.
Назначайте срок годности документам и источникам. Когда данные устаревают, админ команды получает уведомление — вы всегда работаете с актуальной информацией.
Внутренние документы компании уже готовы стать источниками — просто загрузите. Нужны внешние источники? Отправьте запрос — мы подключим всё сами.
Видно, как команда использует платформу: статистика по запросам, популярным темам и эффективности.
Интеграции с существующими корпоративными дисками и системами по запросу.
FAQ
14 ответов для руководителей и специалистов
Ваши документы хранятся в изолированном облачном хранилище с шифрованием при передаче и хранении. Мы не используем ваши данные для обучения моделей.
Сейчас платформа работает как облачный сервис. Версия для развёртывания в закрытом контуре находится в разработке — если для вас это критично, свяжитесь с нами, и мы обсудим сроки и условия пилота.
Вы можете создавать отдельные базы знаний для каждого отдела или настраивать права доступа для каждого сотрудника. Конфиденциальные документы юридического отдела не будут видны маркетингу — и наоборот.
Скорость разворачивания решения на команду из 10–50 человек с настройкой баз знаний ограничена исключительно готовностью ваших данных. Доступ раздаётся за 10 минут. Вы можете сделать это самостоятельно или написать нам для помощи в настройке прав.
Для ориентира, объемная PDF презентация на 200 страниц может загружаться полторы–три минуты в зависимости от количества таблиц, графиков и сканов внутри. Если ваша база знаний состоит из тысяч документов, мы можем организовать ускоренную загрузку.
Точный ROI зависит от вашего сценария — если необходима помощь в подготовке коммерческого обоснования, мы поможем.
Для самостоятельной оценки используйте формулу:
Экономия в месяц = (кол-во сотрудников) × (часов на поиск/анализ в день) × (% ускорения) × (стоимость часа сотрудника) × 22 рабочих дня
Пример: 10 аналитиков × 2 ч/день × 60% ускорение × 2 000 ₽/час × 22 дня = 528 000 ₽/мес.
Пользователь задаёт вопрос на естественном языке и получает ответ со ссылкой на источник. Специального обучения не требуется — если человек умеет пользоваться мессенджером, он справится.
Настройка источников и прав доступа максимально проста и описана в инструкции к платформе, однако, если обучение необходимо, мы его проведём.
PDF, DOC, DOCX, PPT, PPTX.
Платформа «видит» таблицы, графики, диаграммы, сканы, изображения и фотографии в документах. Это возможно благодаря экспертной технологии SupaContext, которая нормализует содержимое. Ответ на вопрос «какая выручка за Q3» будет взят из таблицы, а не угадан из контекста.
Без ограничений по количеству. Максимальный размер одного файла — 400 МБ.
Нет. Новые документы доступны для поиска и анализа сразу после загрузки и обработки. Удаление документов тоже не требует дополнительных действий — база обновляется автоматически.
Поддерживаемые языки для поиска и анализа данных — русский и английский.
Точность поиска и анализа документов подтверждена на базе в 15 000 документов. Каждый ответ сопровождается ссылкой на конкретный фрагмент исходного документа — вы всегда можете проверить источник. ИИ-ассистент работает только с вашими данными и всегда показывает, откуда взят ответ: документ, страница, фрагмент.
Честно скажет, что данные не найдены — без выдумок и додумываний. При этом ассистент может подсказать смежные темы и направления, по которым информация в ваших источниках есть, чтобы вы знали, где продолжить поиск.
Если точная цифра не указана напрямую, но её можно рассчитать по имеющимся данным из источников — ассистент сделает расчёт и покажет, из каких данных и как он получил результат.
От ChatGPT и чат-ботов — ChatGPT генерирует ответы из обучающих данных интернета и не знает ваших внутренних документов. SupaLab работает только с вашими данными: загружает документы, разбирает их структуру и отвечает со ссылкой на конкретную страницу и фрагмент.
От типичных RAG-решений — большинство RAG-систем нарезают документ на фрагменты и ищут по ним через векторный поиск (поиск по похожести). Это работает для простых текстов, но теряет контекст при нарезке, не видит таблицы и графики, и плохо справляется с числовыми данными. SupaLab сначала полностью нормализует документ: распознаёт таблицы, графики, сканы и структуру страниц — и использует многоуровневый поиск, а не только векторный. Поэтому точность ответов выше, особенно на сложных документах.
Платформа поддерживает загрузку документов через интерфейс и API. Синхронизация с Яндекс.диском, Telegram, корпоративными хранилищами и другими системами настраивается по запросу.
Да. SupaContext API — отдельный продукт для подключения ваших ИИ-агентов к базе знаний, где документы приведены к оптимальному формату для работы с ИИ. Напишите нам на privet@supalab.ru — расскажем детали.